
Python3 Cache Decorator
Repeated computation efforts are very annoying. But it is even more annoying, if they take a lot of time because that can get nasty quickly. This is where cache comes to the rescue.
What is cache?
Basically a cache stores data so that it can be returned later. It may sound a bit underwhelming. But what if the requested data takes a lot of time to be fetched or calculated? A quick cache that holds already calculated results can be very powerful then.
Example:
An interesting use case of this would be the calculation of the Fibonacci sequence.
In this sequence, each number is calculated by adding the two previous numbers in the sequence. The first two entries are special as they don't have two preceding members, so they are defined as 0 and 1. But starting from the third one, it gets more interesting. The next number after 1 is 1 again. This of course happens by adding the two previous entries: 0 and 1. By repeating this action, the sequence continues with 2, 3, 5, 8, 13, 21, 34 and so on.
Here a quick example of a program that can calculate fibonacci numbers:

This function calculates the Fibonacci number at the position we give it. It does this by calculating the two preceding numbers, calling itself again (this is called recursion, a topic for another time), and adding them. This gets out of hand quicker than one might think. At first it's not so bad. For the fifth number, the function is called 9 times overall. But this number grows exponentially. For the 10th number, it is already called 109 times. And for the 40t, it takes 204,668,309 calls! This is starting to take quite some time to process as well. The first few numbers go over quickly. It took my computer less then a second to do the first 30 numbers, but for the first 40 numbers it was already one and a half minutes! And it will only go downhill from there.
So now let's introduce the cache!
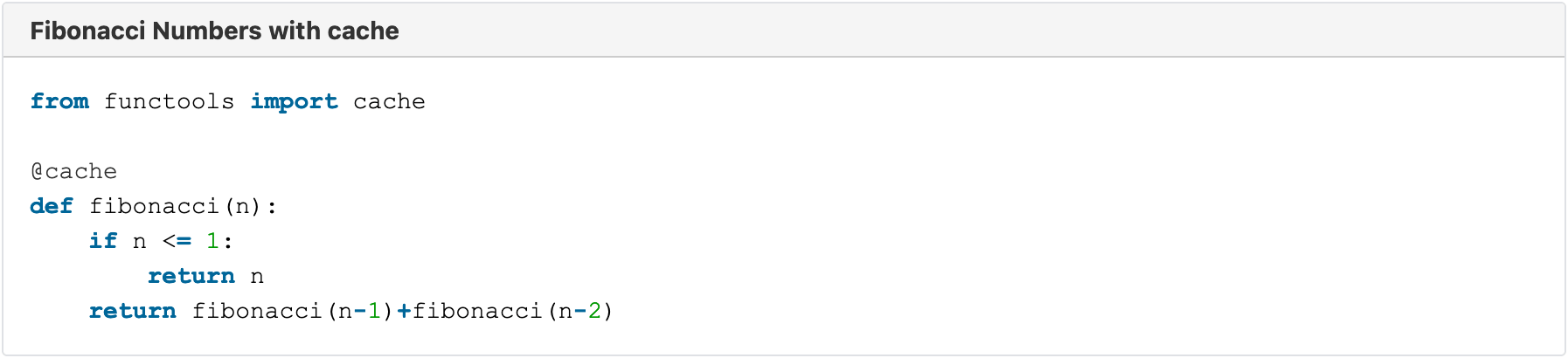
This simple addition dramatically reduces the processing time.
Now the first 40 numbers take 0.0003 seconds. It's a third of a millisecond. This is a 300.000 times improvement! Now it can calculate the first million numbers in a fortieth of a second.
But how does it work?
The cache decorator adds some neat functionality to our function. It caches previous results of the function. The first time the function gets called with a certain parameter, e.g. 4, the function does its thing and calculates the corresponding number (in this case 3). But now the function "remembers" that when it's called with the parameter 4, it just has to return 3, no calculation needed. And that happens for every parameter that could ever be called. In a function like this, where it gets called with the same parameters a lot, it saves a lot of time.
Real world example:
Not every process can be optimized to this degree of course.
But a real world example could look something like this:
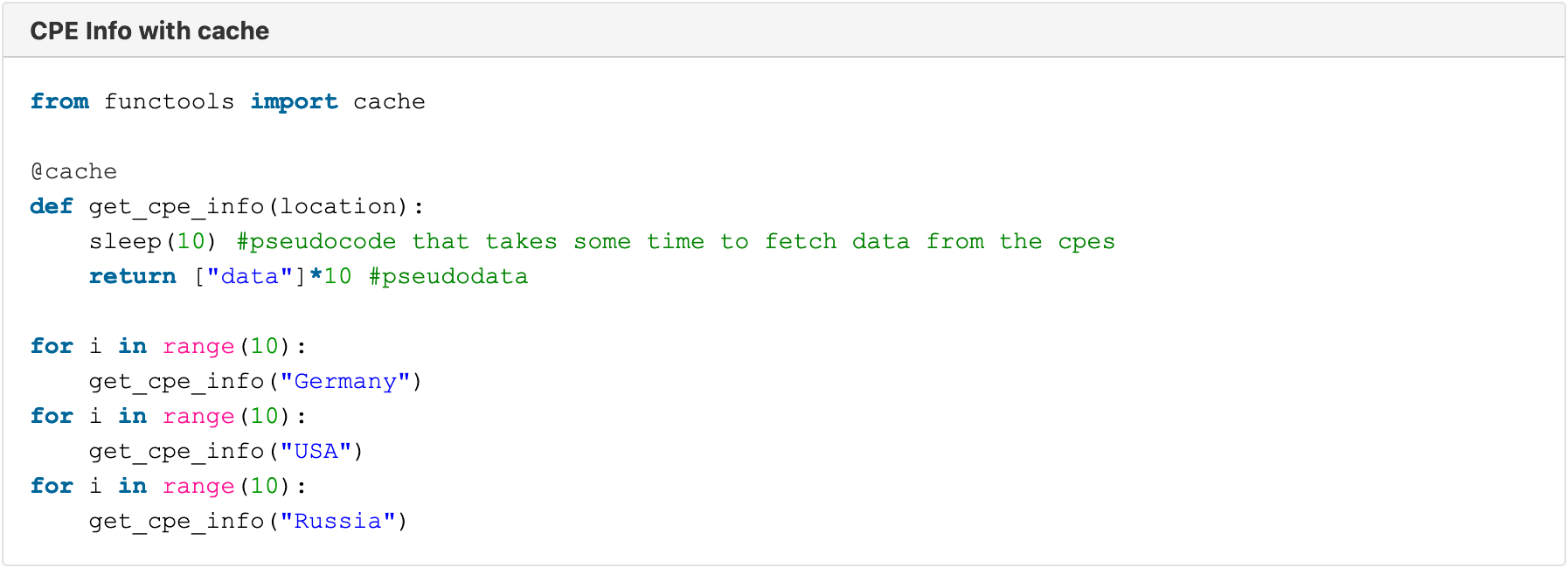
The pseudo function get_cpe_info fetches some data from a lot of CPEs, but only if they are in a given location. This action takes 10 seconds each time it gets executed. This now gets called 10 times for different locations, maybe from different GUIs or other endpoints. Without the cache decorator, these actions would now take 5 minutes overall. But when we add it, only the first user of every country will have to wait for 10 seconds. And everybody else, or even the initial user on reruns, will now get their results practically instantly.
Drawbacks of cache:
As everything else, the cache does not come without its share of drawbacks of course. The first and most obvious one of course is that the cache, at least this implementation of it, does not know if the "real" data in the background has changed. In the previous example, what if a CPE gets moved or disconnected completely? Or if a new one is introduced somewhere? The cache would not pick up on that and would just return the data it calculated on the first call. There are of course multiple ways of fixing or at least minimizing this problem. One way is to reset the cache every now and then. Let's say every 24 hours. But it's no good if the use case is dependent on the newest data at any time.
Another drawback is that this will increase the RAM usage of wherever this is used, because all of the cached data needs to stay somewhere. So if one is in an environment with tight memory optimization or limits, this could become a problem.
Another possible problem is that the result data can be permutated on accident, therefore falsifying the data called at a later time. Let's take a look at this example:

In this example, something is fetching the data and then changing it. By doing that, the reference data in the cache is also altered. The above code prints out this:
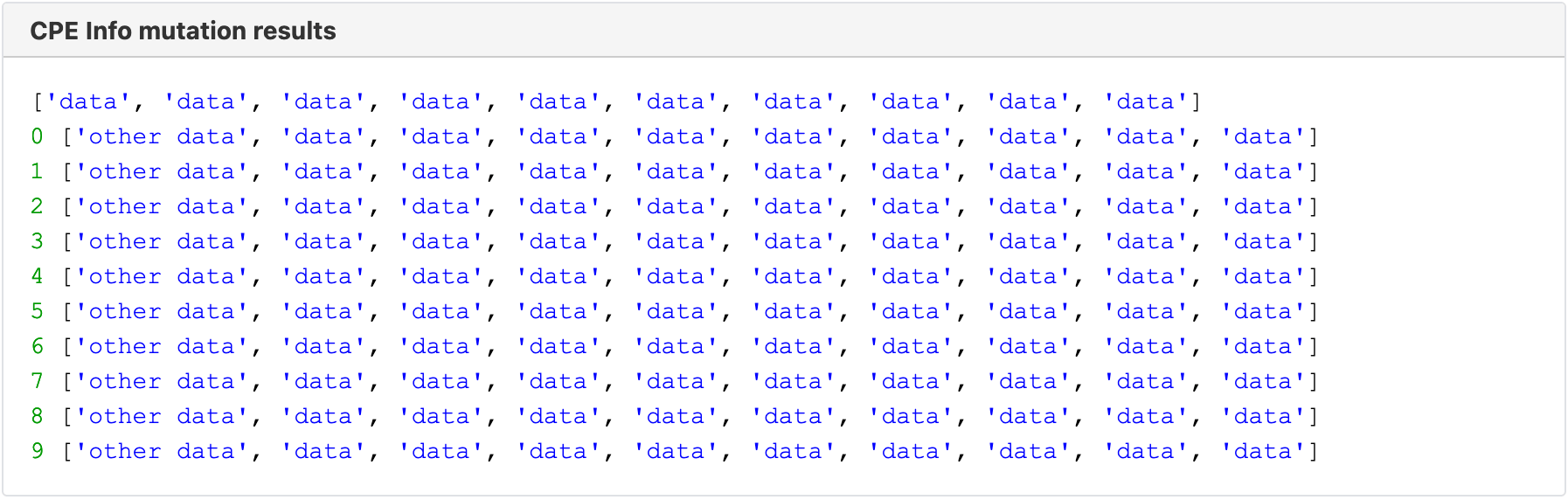
As we can see, the data stays changed in all the later calls of the function as well. When you are aware of this situation though, it can be used to your advantage as well. First of all, there needs to be some access function that fetches the data and then duplicates it, so that the functions on the outside can't mutate it. For example:

Now the result is untouched, just as you would expect:
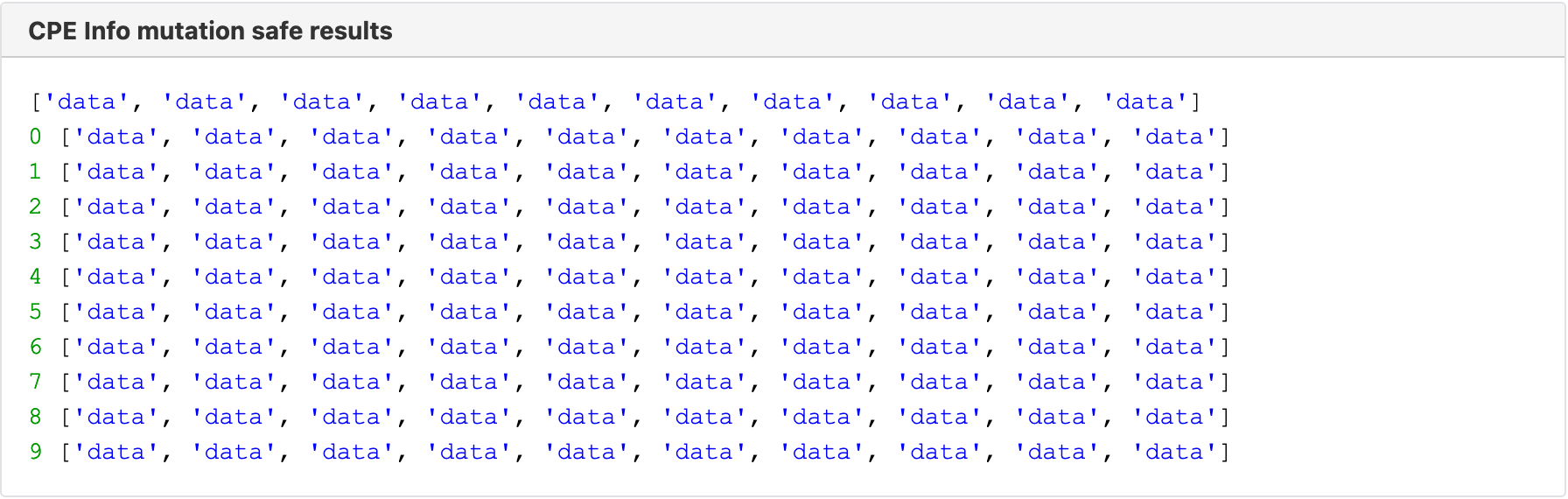
Now the cached data can be modified to our needs. One problem mentioned before is that the data will not be updated, if the real background data changed. Let's introduce a function that changes that:

Here some new data gets added after the first request. In reality, this function would be called by other components of course. But for demonstration purposes it will be done just in line here. The above code produces this output:

And with that you can also have a function that removes CPEs out of the cache, if they get removed from that location.
The cache decorator can be very powerful when used correctly. When the limitations and drawbacks are kept in mind, it can save a lot of time.